27 stycznia 2026 roku OpenAI opublikowało niezwykle szczegółowe notatki inżynieryjne wyjaśniające, w jaki sposób Codex CLI — firmowy agent kodujący działający w wierszu poleceń — w rzeczywistości obsługuje konwersacje, wywołuje narzędzia i zarządza kontekstem.
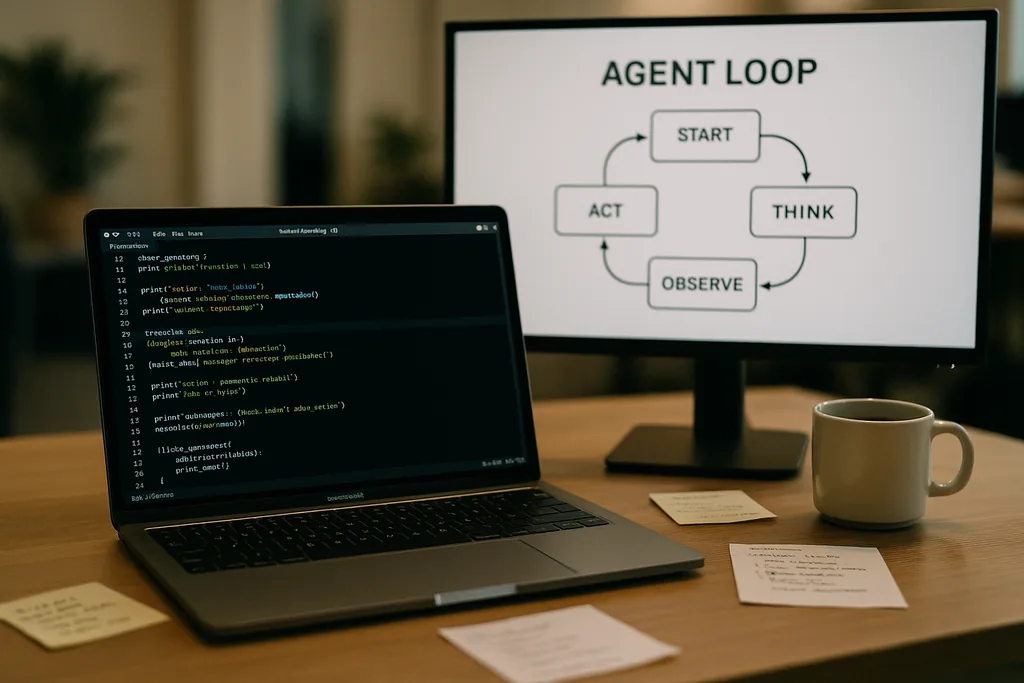
Jak wygląda pętla agenta
Sercem Codex CLI jest prosty, powtarzalny wzorzec, który inżynierowie nazywają „pętlą agenta” (agent loop): przyjmij dane wejściowe użytkownika, stwórz prompt, poproś model o odpowiedź, zareaguj na wywołania narzędzi żądane przez model, dołącz wyniki działania narzędzi do konwersacji i powtarzaj, aż model zwróci ostateczną wiadomość asystenta.
Ten wzorzec brzmi prosto, ale dokumentacja ujawnia wiele drobnych decyzji projektowych, które wspólnie kształtują wydajność i niezawodność. Prompt wysyłany do modelu nie jest pojedynczym blokiem tekstu; to ustrukturyzowany zestaw priorytetyzowanych komponentów. Role systemu (system), dewelopera (developer), asystenta (assistant) i użytkownika (user) określają, które instrukcje mają pierwszeństwo. Pole narzędzi (tools) informuje o dostępnych funkcjach — lokalnych poleceniach powłoki, narzędziach do planowania, wyszukiwarce internetowej i niestandardowych usługach udostępnianych za pośrednictwem serwerów Model Context Protocol (MCP). Kontekst środowiska opisuje uprawnienia piaskownicy (sandbox), katalogi robocze oraz to, które pliki lub procesy są widoczne dla agenta.
Wywołania narzędzi, MCP i sandboxing
Gdy model generuje wywołanie narzędzia, Codex wykonuje je w kontrolowanym środowisku (swojej piaskownicy), przechwytuje dane wyjściowe i dołącza wynik do konwersacji. Niestandardowe narzędzia mogą być wdrażane poprzez serwery MCP — otwarty standard przyjęty przez kilka firm — który pozwala modelowi odkrywać i wywoływać możliwości wykraczające poza prostą powłokę. Dokumentacja omawia również konkretne błędy, które zespół odkrył podczas budowania tych integracji — na przykład niespójną enumerację narzędzi MCP — które musiały zostać naprawione.
OpenAI zauważa, że sandboxing i dostęp do narzędzi to obszary, którym zostaną poświęcone kolejne posty. Początkowa dokumentacja skupia się na mechanice pętli i mitygacji problemów z wydajnością, a nie na pełnym modelu zagrożeń związanym z agentami posiadającymi uprawnienia do zapisu w systemie plików lub usługach sieciowych.
Żądania bezstanowe, wybory dotyczące prywatności i koszt kopiowania kontekstu
Wzrost rozmiaru danych nie jest liniowy. Każda tura dodaje tokeny, a ponieważ każda tura zawiera w całości wszystkie poprzednie, rozmiar promptu wykazuje tendencję do wzrostu kwadratowego względem liczby tur. Zespół dokumentuje to wprost i wyjaśnia, w jaki sposób ogranicza to zjawisko poprzez kompaktowanie kontekstu i buforowanie promptów.
Buforowanie promptów i dokładne prefiksy
Buforowanie promptów (prompt caching) to pragmatyczna optymalizacja: jeśli nowe żądanie zawiera dokładny prefiks wcześniej buforowanego promptu, dostawca może ponownie wykorzystać obliczenia i szybciej zwrócić wyniki. Jednak pamięć podręczna wymaga sztywności. Każda zmiana dostępnych narzędzi, zmiana modelu, a nawet drobna korekta konfiguracji piaskownicy może unieważnić prefiks i zmienić trafienie w pamięci podręcznej w kosztowne pudło. Inżynierowie OpenAI ostrzegają, że deweloperzy powinni unikać rekonfiguracji w trakcie konwersacji, jeśli zależy im na spójnym czasie reakcji.
Trafienia w pamięci podręcznej zależą od dokładnego dopasowania prefiksu, więc rozsądną praktyką jest przypinanie manifestów narzędzi i utrzymywanie stałego wyboru modelu w ramach trwającej interakcji. Gdy pudła w pamięci podręcznej zdarzają się często, system degraduje się do pełnego przetwarzania przy każdym wywołaniu — dokładnie wtedy, gdy deweloperzy oczekują, że agent będzie działał błyskawicznie.
Kompaktowanie kontekstu: kompresja przeszłości bez utraty znaczenia
Aby zarządzać wzrostem liczby tokenów, Codex implementuje automatyczne kompaktowanie kontekstu (context compaction). Zamiast pozostawiać to poleceniu użytkownika, CLI wywołuje wyspecjalizowany punkt końcowy API, który kompresuje starsze tury konwersacji w zaszyfrowany element treści, zachowując jednocześnie podsumowaną wiedzę niezbędną modelowi do kontynuowania pracy. Wcześniejsze wersje wymagały ręcznego kompaktowania przez użytkownika; nowsze podejście przenosi ten proces do wywołania API, które zachowuje pamięć roboczą modelu.
Kompaktowanie zmniejsza koszt tokenów, ale wprowadza pewne niuanse: podsumowania muszą być na tyle wierne, aby zapobiec halucynacjom w dalszej części pracy, właściwości szyfrowania muszą odpowiadać ograniczeniom prywatności, a heurystyki kompaktowania muszą decydować, które elementy stanu są kluczowe, a które można pominąć. Dokumentacja oznacza te kwestie jako otwarte wyzwania inżynieryjne, a nie ostateczne rozwiązania.
Praktyczne ograniczenia i doświadczenia deweloperów
Notatki OpenAI szczerze mówią o mocnych i słabych stronach. W przypadku prostych zadań — typu szkieletowanie (scaffolding), tworzenie kodu powtarzalnego (boilerplate) czy szybkie prototypowanie, w których agenci kodujący przodują — Codex jest szybki i przydatny. W przypadku głębszej pracy inżynieryjnej, wymagającej dużego kontekstu, którego model nie widział w swoich danych treningowych, agent staje się kruchy. Wygeneruje obiecujące szkielety, a następnie utknie lub wygeneruje nieprawidłowe kroki, które wymagają ludzkiego debugowania.
Inżynierowie testujący Codex wewnętrznie stwierdzili, że agent może drastycznie przyspieszyć początkowe tworzenie projektu, ale nie jest jeszcze w stanie zastąpić iteracyjnego, eksperckiego debugowania, którego wymaga solidna inżynieria. Zespół potwierdził również, że używa Codex do budowy części samego Codex — praktyka ta rodzi interesujące pytania o pętle zwrotne w narzędziach trenowanych na własnych wynikach.
Dlaczego OpenAI to ujawniło — transparentność, konkurencja i standardy
Opublikowanie dogłębnej analizy wewnętrznej inżynierii produktu konsumenckiego jest godne uwagi w przypadku firmy, która zazwyczaj strzegła swoich szczegółów operacyjnych. Ujawnienie informacji przez OpenAI zbiega się w czasie z szerszym dążeniem ekosystemu w stronę standardów agentowych: Anthropic i OpenAI wspierają MCP w celu odkrywania i wywoływania narzędzi, a obie firmy publikują klientów CLI jako open source, aby deweloperzy mogli sprawdzać zachowanie systemu od początku do końca.
Transparentność służy kilku grupom odbiorców. Deweloperzy otrzymują wzorce implementacji i praktyczne porady dotyczące budowania niezawodnych agentów. Inżynierowie ds. bezpieczeństwa mogą analizować kompromisy między piaskownicą a dostępem do narzędzi. Konkurenci i społeczność zajmująca się standardami mogą szybciej wprowadzać innowacje, ponieważ nie muszą stosować inżynierii wstecznej wobec zachowania klientów, aby zapewnić interoperacyjność.
Porady operacyjne dla zespołów korzystających z agentów kodujących
- Przypinaj modele i manifesty narzędzi w ramach sesji, aby zmaksymalizować trafienia w pamięci podręcznej promptów i uzyskać stabilną wydajność.
- Proaktywnie stosuj kompaktowanie kontekstu przy długich zadaniach, aby kontrolować koszty tokenów i unikać niekontrolowanego wzrostu promptów.
- Ograniczaj uprawnienia agenta i izoluj foldery z prawem zapisu w piaskownicach, aby zredukować przypadkowe lub złośliwe skutki uboczne.
- Przewiduj czas na ręczne debugowanie: agenci przyspieszają szkieletowanie i iterację, ale nie zastępują jeszcze eksperckiego rozumowania nad złożonymi bazami kodu.
Co dalej
Inżynier będący autorem wpisu zasygnalizował kontynuacje, które bardziej szczegółowo obejmą architekturę CLI, implementację narzędzi oraz model sandboxingu. Te przyszłe wpisy będą miały znaczenie: w miarę jak agenci zyskują głębszy dostęp do środowisk deweloperskich, mechanika bezpiecznego wykonywania, pochodzenie danych (provenance) i weryfikowalne wywoływanie narzędzi zdecydują o tym, czy zespoły przyjmą ich jako asystentów, czy potraktują jako ryzykowne ciekawostki.
Na razie notatki OpenAI zamieniają część mistycyzmu wokół agentów kodujących w konkretne pokrętła i dźwignie. Ta zmiana ułatwia zespołom inżynieryjnym planowanie wokół znanych kompromisów — wydajności, prywatności i kruchości — zamiast odkrywania ich w bolesny sposób podczas awarii produkcyjnych.
Dokumentacja Codex CLI jest zaproszeniem: zapoznaj się z implementacją, przetestuj przypadki brzegowe i projektuj przepływy pracy, które akceptują ograniczenia, jednocześnie wykorzystując wyraźne korzyści. W branży ścigającej się o wprowadzenie agentów do codziennych narzędzi programistycznych, jasność co do trybów awaryjnych jest najrzadszym i najbardziej użytecznym towarem.
Źródła
- OpenAI (dokumentacja: "Unrolling the Codex agent loop")
- Anthropic (specyfikacja Model Context Protocol i materiały Claude Code)
- Repozytoria inżynieryjne OpenAI i notatki z implementacji Codex CLI

Comments
No comments yet. Be the first!