2026年1月27日,OpenAI发布了异常详尽的技术工程笔记,解释了其命令行编程智能体(coding agent)Codex CLI实际上是如何运行对话、调用工具以及管理上下文的。
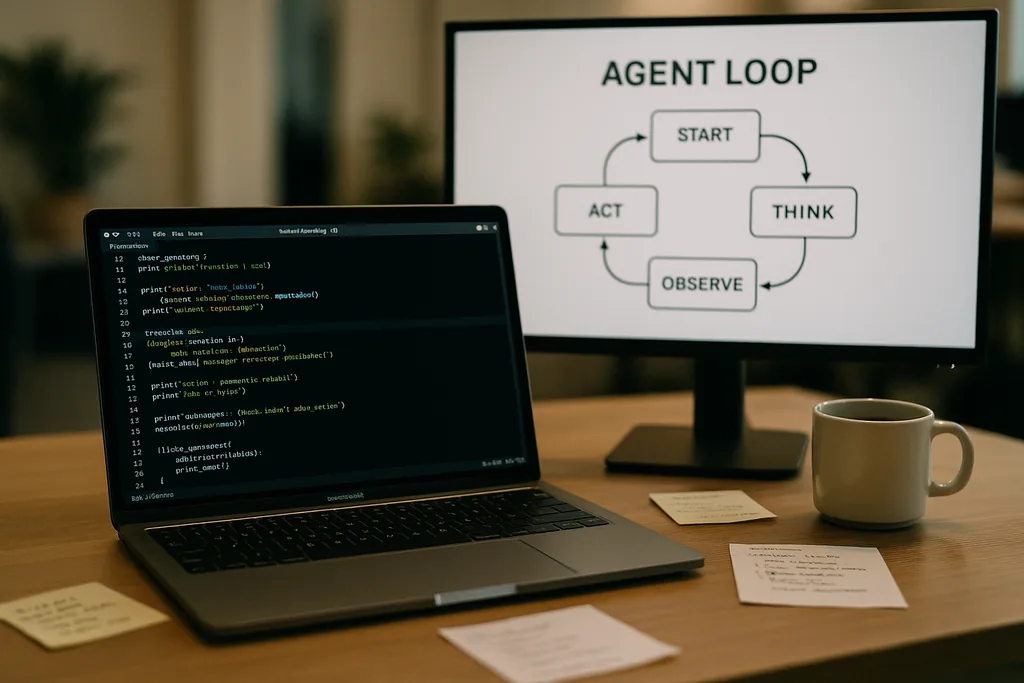
智能体循环的运作方式
Codex CLI的核心是一个被工程师称为“智能体循环”(agent loop)的简单重复模式:接收用户输入、构建提示词、请求模型响应、执行模型请求的工具调用、将工具输出追加到对话中,并不断重复,直到模型返回最终的助手消息。
这种模式听起来很直观,但文档揭示了许多共同决定性能和可靠性的微小设计决策。发送给模型的提示词并非一段单一的文本,而是由具有优先级的组件构成的结构化组合。系统(system)、开发者(developer)、助手(assistant)和用户(user)角色决定了哪些指令具有优先权。工具字段则声明了可用功能——包括本地 shell 命令、规划工具、网页搜索,以及通过模型上下文协议(Model Context Protocol,简称 MCP)服务器提供的自定义服务。环境上下文则描述了沙箱权限、工作目录以及智能体可见的文件或进程。
工具调用、MCP 与沙箱机制
当模型发出工具调用时,Codex 会在一个受控环境(即沙箱)中执行该工具,捕获输出,并将结果追加到对话中。自定义工具可以通过 MCP 服务器实现——这是一种已被多家公司采用的开放标准——它允许模型发现并调用超出简单 shell 范围的功能。文档还讨论了团队在构建这些集成时发现的具体 bug(例如 MCP 工具的枚举不一致),并已对其进行了修复。
OpenAI 指出,沙箱和工具访问权限是后续文章将深入探讨的活跃领域。初期的文档重点在于循环机制和性能优化,而非具有文件系统或网络服务写入权限的智能体的完整威胁模型。
无状态请求、隐私选择与上下文复制成本
这种膨胀并非线性的。每一轮对话都会增加 token,由于每一轮都完整包含之前的回合,提示词的大小往往会相对于对话轮数呈二次方增长。团队明确记录了这一点,并解释了他们如何通过上下文压缩和提示词缓存来缓解这一问题。
提示词缓存与精确前缀
提示词缓存是一项实用的优化:如果一个新请求是之前已缓存提示词的精确前缀,服务商就可以复用计算结果并更快地返回响应。但缓存要求高度的一致性。对可用工具的任何更改、模型切换、甚至是沙箱配置的微调,都可能导致前缀失效,使缓存命中变成代价高昂的未命中。OpenAI 工程师警告说,如果开发者需要稳定的延迟,应避免在对话中途重新进行配置。
缓存命中取决于精确的前缀匹配,因此明智的做法包括固定工具清单(manifests),并在持续的交互中保持模型选择不变。当缓存未命中频繁发生时,系统在每次调用时都会退化为完全重新处理——而这恰恰是开发者期望智能体反应敏捷的时候。
上下文压缩:在不损失含义的情况下压缩过往信息
为了管理 token 的增长,Codex 实现了自动上下文压缩。CLI 不再依赖用户命令,而是调用一个专门的 API 终端,将旧的对话轮次压缩为加密内容项,同时保留模型继续运行所需的总结性知识。早期的版本需要用户手动进行压缩;而新方法将这一过程整合进 API 调用中,从而保留模型的“工作记忆”。
压缩降低了 token 成本,但也带来了一些微妙的挑战:摘要必须足够准确以防止后续产生幻觉,加密属性需要符合隐私限制,且压缩启发式算法必须决定状态中的哪些部分是必不可少的,哪些是可舍弃的。文档将这些标记为尚在探索中的工程选择,而非定论设计。
实际局限性与开发者体验
OpenAI 的笔记坦诚地指出了其优缺点。对于简单的任务——如编程智能体所擅长的基础框架搭建、样板代码生成或快速原型设计——Codex 既快速又实用。但对于模型训练数据中未见过的、依赖大量上下文的深度工程工作,该智能体则显得脆弱。它会生成看似有希望的基础框架,然后停滞不前,或输出需要人工调试的错误步骤。
内部测试 Codex 的工程师发现,该智能体可以显著加速项目的初始创建,但尚不能取代严谨工程所需的迭代式专家调试。团队还证实,他们正使用 Codex 来构建 Codex 自身的部分内容——这种做法引发了关于模型基于自身输出进行训练的反馈循环这一有趣问题。
OpenAI 为何公开这些信息——透明度、竞争与标准
对于一家通常对其运营细节保密的公司来说,发布关于消费级产品内部工程的深入探讨是值得关注的。OpenAI 的这一披露恰逢整个生态系统推动智能体标准化的浪潮:Anthropic 和 OpenAI 都支持用于工具发现和调用的 MCP,并且都发布了开源的 CLI 客户端,以便开发者可以端到端地检查其行为。
这种透明度为多个群体提供了帮助。开发者获得了构建可靠智能体的实现模式和实用建议。注重安全的工程师可以审查沙箱和工具访问权限的权衡。竞争对手和标准社区可以更快地进行迭代,因为他们不需要为了实现互操作而对客户端行为进行逆向工程。
给使用编程智能体团队的运营建议
- 在会话中固定模型和工具清单,以最大化提示词缓存命中率并获得稳定的性能。
- 在执行长任务时主动使用上下文压缩,以控制 token 成本并避免提示词失控增长。
- 限制智能体权限并在沙箱中隔离可写文件夹,以减少意外或恶意的副作用。
- 预留人工调试的时间和预算:智能体可以加速基础框架的搭建和迭代,但它们目前还无法取代专家对复杂代码库的推理。
未来展望
撰写该博文的工程师表示,后续内容将更深入地涵盖 CLI 的架构、工具实现以及沙箱模型。这些未来的内容至关重要:随着智能体能够更深入地访问开发者的环境,安全执行机制、溯源以及可验证的工具调用将决定团队是将其作为助手采用,还是将其视为有风险的新奇事物。
就目前而言,OpenAI 的笔记将围绕编程智能体的一些神秘感转化为了具体的“旋钮和杠杆”。这种转变使得工程团队更容易围绕已知的权衡(性能、隐私和脆弱性)进行规划,而不是在生产环境中断期间才艰难地发现这些问题。
Codex CLI 的文档是一份邀请:阅读实现细节、测试边缘情况,并设计既能接受局限性又能利用其显著优势的工作流。在一个竞相将智能体引入日常开发者工具的行业中,对故障模式的清晰认识是最稀缺也最有用的商品。
Sources
- OpenAI(文档:“Unrolling the Codex agent loop”)
- Anthropic(Model Context Protocol 规范和 Claude Code 相关资料)
- OpenAI 工程仓库和 Codex CLI 实现笔记

Comments
No comments yet. Be the first!