Il 27 gennaio 2026 OpenAI ha pubblicato note ingegneristiche insolitamente dettagliate che spiegano come Codex CLI — l'agente di codifica a riga di comando dell'azienda — gestisca effettivamente le conversazioni, chiami gli strumenti e amministri il contesto.
Com'è strutturato il loop dell'agente
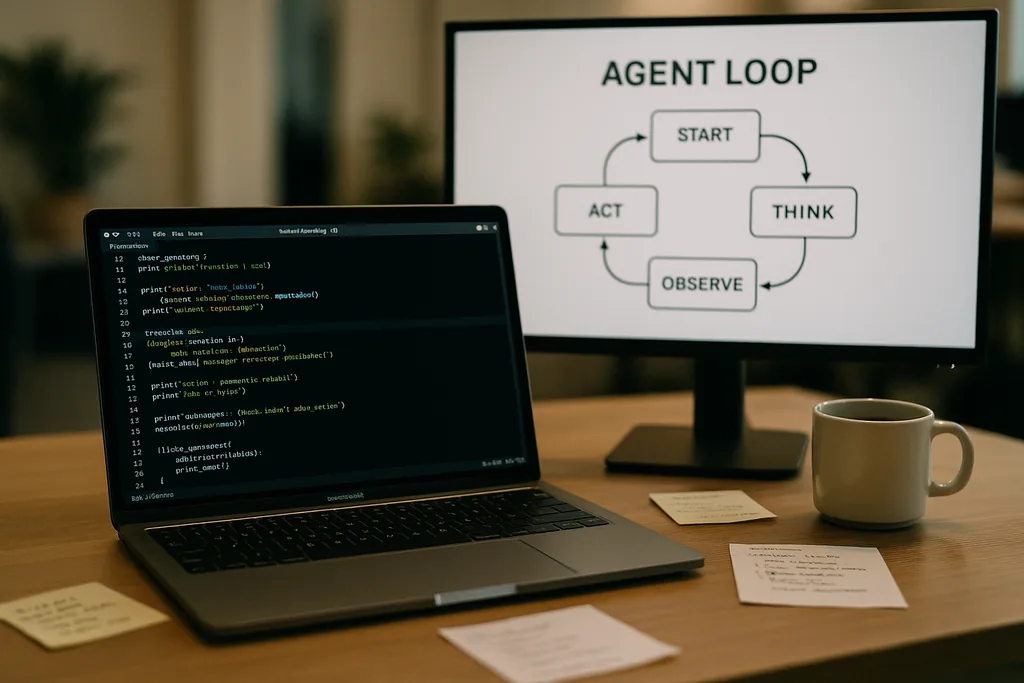
Al cuore di Codex CLI c'è un semplice schema ripetitivo che gli ingegneri chiamano "loop dell'agente": accettare l'input dell'utente, elaborare un prompt, chiedere una risposta al modello, agire sulle chiamate agli strumenti (tool call) richieste dal modello, aggiungere gli output degli strumenti alla conversazione e ripetere finché il modello non restituisce un messaggio finale dell'assistente.
Questo schema sembra lineare, ma la documentazione approfondisce molte piccole decisioni di design che, insieme, determinano prestazioni e affidabilità. Il prompt inviato al modello non è un singolo blocco di testo; è un assemblaggio strutturato di componenti prioritari. I ruoli system, developer, assistant e user determinano quali istruzioni hanno la precedenza. Un campo "tools" pubblicizza le funzioni disponibili: comandi shell locali, utility di pianificazione, ricerca web e servizi personalizzati esposti tramite server Model Context Protocol (MCP). Il contesto dell'ambiente descrive i permessi della sandbox, le directory di lavoro e quali file o processi sono visibili all'agente.
Chiamate agli strumenti, MCP e sandboxing
Quando il modello emette una chiamata a uno strumento, Codex esegue tale strumento in un ambiente controllato (la sua sandbox), acquisisce l'output e aggiunge il risultato alla conversazione. Gli strumenti personalizzati possono essere implementati tramite server MCP — uno standard aperto adottato da diverse aziende — che consentono a un modello di scoprire e invocare funzionalità che vanno oltre una semplice shell. La documentazione discute anche bug specifici scoperti dal team durante la creazione di queste integrazioni — ad esempio, un'enumerazione incoerente degli strumenti MCP — che hanno dovuto essere corretti.
OpenAI osserva che il sandboxing e l'accesso agli strumenti sono aree attive per i post successivi. La documentazione iniziale si concentra sulla meccanica del loop e sulla mitigazione delle prestazioni piuttosto che sul modello di minaccia completo di agenti con accesso in scrittura a un filesystem o a servizi di rete.
Richieste stateless, scelte sulla privacy e il costo della copia del contesto
L'inflazione del contesto non è lineare. Ogni turno aggiunge token e, poiché ogni turno include integralmente i turni precedenti, la dimensione del prompt tende a una crescita quadratica rispetto al numero di turni. Il team documenta esplicitamente questo fenomeno e spiega come lo mitiga con la compattazione del contesto e il caching dei prompt.
Caching dei prompt e prefissi esatti
Il caching dei prompt è un'ottimizzazione pragmatica: se una nuova richiesta è un prefisso esatto di un prompt precedentemente memorizzato in cache, il provider può riutilizzare il calcolo e restituire i risultati più velocemente. Ma le cache richiedono rigidità. Qualsiasi modifica agli strumenti disponibili, un cambio di modello o persino una modifica alla configurazione della sandbox può invalidare il prefisso e trasformare un successo della cache (cache hit) in un costoso fallimento (cache miss). Gli ingegneri di OpenAI avvertono che gli sviluppatori dovrebbero evitare la riconfigurazione a metà conversazione quando hanno bisogno di una latenza costante.
I successi della cache dipendono dalla corrispondenza esatta del prefisso, quindi le buone pratiche includono il blocco dei manifest degli strumenti e il mantenimento costante della selezione del modello all'interno di un'interazione in corso. Quando i fallimenti della cache si verificano frequentemente, il sistema degrada verso una rielaborazione completa ad ogni chiamata, proprio quando gli sviluppatori si aspettano che l'agente sia più reattivo.
Compattazione del contesto: comprimere il passato senza perdere il significato
Per gestire la crescita dei token, Codex implementa la compattazione automatica del contesto. Invece di affidarla a un comando dell'utente, la CLI chiama un endpoint API specializzato che comprime i turni di conversazione più vecchi in un elemento di contenuto crittografato, mantenendo al contempo le conoscenze sintetizzate di cui il modello ha bisogno per procedere. Le versioni precedenti richiedevano la compattazione manuale da parte dell'utente; il nuovo approccio sposta il processo in una chiamata API che preserva la memoria di lavoro del modello.
La compattazione riduce il costo dei token ma introduce alcune sottigliezze: i riassunti devono essere sufficientemente fedeli da prevenire allucinazioni a valle, i supporti di crittografia devono corrispondere ai vincoli di privacy e le euristiche di compattazione devono decidere quali parti dello stato siano essenziali rispetto a quelle sacrificabili. La documentazione segnala queste come scelte ingegneristiche ancora aperte piuttosto che come design definitivi.
Limiti pratici ed esperienza dello sviluppatore
Le note di OpenAI sono sincere riguardo ai punti di forza e di debolezza. Per compiti semplici — il tipo di scaffolding, codice boilerplate o prototipazione rapida in cui gli agenti di codifica eccellono — Codex è veloce e utile. Per lavori di ingegneria più profondi e densi di contesto che il modello non ha visto nei suoi dati di addestramento, l'agente è fragile. Genererà impalcature promettenti, per poi bloccarsi o produrre passaggi errati che richiedono il debugging umano.
Gli ingegneri che hanno testato Codex internamente hanno scoperto che l'agente può accelerare drasticamente la creazione iniziale del progetto, ma non può ancora sostituire il debugging esperto e iterativo richiesto da una solida ingegneria. Il team ha anche confermato di utilizzare Codex per costruire parti di Codex stesso — una pratica che solleva interessanti questioni di feedback sugli strumenti addestrati sui propri output.
Perché OpenAI ha aperto questi dati: trasparenza, concorrenza e standard
La pubblicazione di un approfondimento tecnico sull'ingegneria interna di un prodotto di consumo è degna di nota per un'azienda che solitamente ha protetto i propri dettagli operativi. La divulgazione di OpenAI coincide con una spinta più ampia dell'ecosistema verso gli standard degli agenti: Anthropic e OpenAI supportano entrambi MCP per la scoperta e l'invocazione degli strumenti, ed entrambi pubblicano client CLI come open source in modo che gli sviluppatori possano ispezionare il comportamento end-to-end.
La trasparenza serve a diversi tipi di pubblico. Gli sviluppatori ottengono modelli di implementazione e consigli pratici per costruire agenti affidabili. Gli ingegneri attenti alla sicurezza possono esaminare i compromessi tra sandbox e accesso agli strumenti. I concorrenti e la comunità degli standard possono iterare più velocemente perché non hanno bisogno di decodificare il comportamento del client per interoperare.
Consigli operativi per i team che utilizzano agenti di codifica
- Bloccare i modelli e i manifest degli strumenti all'interno di una sessione per massimizzare i successi della cache dei prompt e la stabilità delle prestazioni.
- Utilizzare proattivamente la compattazione del contesto per compiti lunghi, al fine di controllare i costi dei token ed evitare una crescita incontrollata dei prompt.
- Limitare i permessi dell'agente e isolare le cartelle scrivibili nelle sandbox per ridurre effetti collaterali accidentali o dannosi.
- Prevedere e pianificare il debugging manuale: gli agenti accelerano lo scaffolding e l'iterazione, ma non sostituiscono ancora il ragionamento esperto su codebase complesse.
Cosa succederà dopo
L'ingegnere che ha scritto il post ha annunciato successivi approfondimenti che copriranno più in dettaglio l'architettura della CLI, l'implementazione degli strumenti e il modello di sandboxing. Questi contributi futuri saranno fondamentali: man mano che gli agenti ottengono un accesso più profondo agli ambienti degli sviluppatori, la meccanica dell'esecuzione sicura, la provenienza e l'invocazione verificabile degli strumenti determineranno se i team li adotteranno come assistenti o li tratteranno come curiosità rischiose.
Per ora, le note di OpenAI trasformano parte del misticismo che circonda gli agenti di codifica in leve e manopole concrete. Questo cambiamento rende più facile per i team di ingegneria pianificare in base a compromessi noti — prestazioni, privacy e fragilità — piuttosto che scoprirli nel modo più difficile durante i disservizi in produzione.
La documentazione di Codex CLI è un invito: leggere l'implementazione, testare i casi limite e progettare flussi di lavoro che accettino i limiti sfruttandone al contempo i chiari vantaggi. In un settore che corre per inserire gli agenti negli strumenti di sviluppo quotidiani, la chiarezza sulle modalità di fallimento è la merce più rara e utile.
Fonti
- OpenAI (documentazione: "Unrolling the Codex agent loop")
- Anthropic (specifiche del Model Context Protocol e materiali di Claude Code)
- Repository di ingegneria OpenAI e note di implementazione di Codex CLI

Comments
No comments yet. Be the first!