Le 27 janvier 2026, OpenAI a publié des notes d'ingénierie inhabituellement détaillées expliquant comment Codex CLI — l'agent de codage en ligne de commande de l'entreprise — gère réellement les conversations, appelle les outils et administre le contexte.
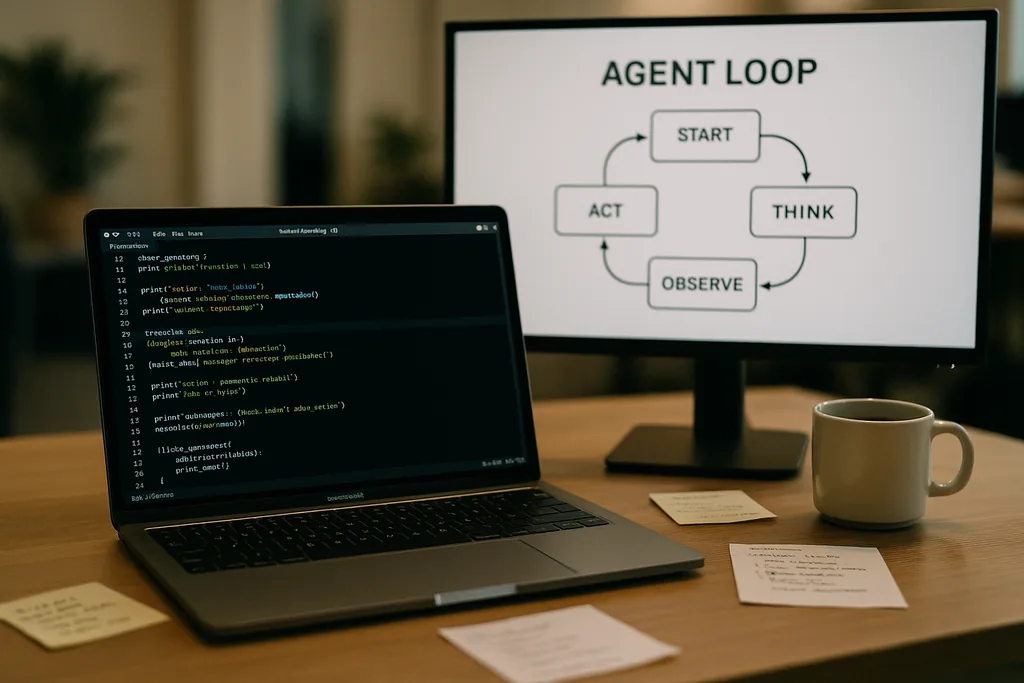
À quoi ressemble la boucle de l'agent
Au cœur de Codex CLI se trouve un modèle répétitif simple que les ingénieurs appellent la « boucle de l'agent » : accepter l'entrée de l'utilisateur, élaborer un prompt, demander une réponse au modèle, agir sur les appels d'outils demandés par le modèle, ajouter les sorties d'outils à la conversation, et répéter jusqu'à ce que le modèle renvoie un message final de l'assistant.
Ce modèle semble simple, mais la documentation détaille de nombreuses petites décisions de conception qui, ensemble, façonnent la performance et la fiabilité. Le prompt envoyé au modèle n'est pas un bloc de texte unique ; c'est un assemblage structuré de composants hiérarchisés. Les rôles de système, de développeur, d'assistant et d'utilisateur déterminent quelles instructions sont prioritaires. Un champ d'outils présente les fonctions disponibles — commandes shell locales, utilitaires de planification, recherche web et services personnalisés exposés via des serveurs Model Context Protocol (MCP). Le contexte de l'environnement décrit les permissions du bac à sable, les répertoires de travail et les fichiers ou processus visibles par l'agent.
Appels d'outils, MCP et sandboxing
Lorsque le modèle émet un appel d'outil, Codex exécute cet outil dans un environnement contrôlé (son bac à sable), capture la sortie et ajoute le résultat à la conversation. Des outils personnalisés peuvent être implémentés via des serveurs MCP — un standard ouvert adopté par plusieurs entreprises — qui permettent à un modèle de découvrir et d'invoquer des capacités au-delà d'un simple shell. La documentation aborde également des bugs spécifiques découverts par l'équipe lors de la création de ces intégrations — une énumération incohérente des outils MCP, par exemple — qui ont dû être corrigés.
OpenAI note que le sandboxing et l'accès aux outils sont des sujets prévus pour des publications ultérieures. La documentation initiale se concentre sur la mécanique de la boucle et l'atténuation des problèmes de performance plutôt que sur le modèle de menace complet d'agents disposant d'un accès en écriture à un système de fichiers ou à des services réseau.
Requêtes sans état, choix de confidentialité et coût de la copie du contexte
Cette inflation n'est pas linéaire. Chaque tour ajoute des tokens, et comme chaque tour inclut l'intégralité des tours précédents, la taille du prompt tend vers une croissance quadratique par rapport au nombre de tours. L'équipe documente cela explicitement et explique comment elle l'atténue grâce à la compaction de contexte et à la mise en cache des prompts.
Mise en cache des prompts et préfixes exacts
La mise en cache des prompts est une optimisation pragmatique : si une nouvelle requête est un préfixe exact d'un prompt précédemment mis en cache, le fournisseur peut réutiliser les calculs et renvoyer les résultats plus rapidement. Mais les caches exigent de la rigidité. Tout changement des outils disponibles, un changement de modèle, ou même un ajustement de la configuration du bac à sable peut invalider le préfixe et transformer un succès de cache en un échec coûteux. Les ingénieurs d'OpenAI avertissent que les développeurs devraient éviter les reconfigurations en milieu de conversation lorsqu'ils ont besoin d'une latence constante.
Les succès de cache dépendent d'une correspondance exacte des préfixes ; les bonnes pratiques consistent donc à figer les manifestes d'outils et à maintenir constante la sélection du modèle au sein d'une interaction en cours. Lorsque les échecs de cache sont fréquents, le système se dégrade en effectuant un retraitement complet à chaque appel — précisément au moment où les développeurs s'attendent à ce que l'agent soit réactif.
Compaction de contexte : compresser le passé sans perdre le sens
Pour gérer la croissance des tokens, Codex implémente une compaction automatique du contexte. Plutôt que de s'en remettre à une commande utilisateur, le CLI appelle un point de terminaison d'API spécialisé qui compresse les anciens tours de conversation dans un élément de contenu chiffré, tout en conservant les connaissances résumées dont le modèle a besoin pour continuer. Les versions précédentes nécessitaient une compaction manuelle par l'utilisateur ; la nouvelle approche intègre le processus dans un appel d'API qui préserve la mémoire de travail du modèle.
La compaction réduit le coût en tokens mais introduit quelques subtilités : les résumés doivent être assez fidèles pour éviter les hallucinations en aval, les paramètres de chiffrement doivent correspondre aux contraintes de confidentialité, et les heuristiques de compaction doivent décider quels éléments de l'état sont essentiels par rapport à ceux qui sont superflus. La documentation signale qu'il s'agit de choix d'ingénierie ouverts plutôt que de conceptions figées.
Limites pratiques et expérience développeur
Les notes d'OpenAI sont franches sur les forces et les faiblesses. Pour des tâches simples — le type d'échafaudage, de code passe-partout ou de prototypage rapide dans lequel les agents de codage excellent — Codex est rapide et utile. Pour un travail d'ingénierie plus profond et riche en contexte que le modèle n'a pas vu dans ses données d'entraînement, l'agent est fragile. Il générera des structures prometteuses, puis stagnera ou produira des étapes incorrectes nécessitant un débogage humain.
Les ingénieurs testant Codex en interne ont constaté que l'agent peut accélérer considérablement la création initiale de projets, mais ne peut pas encore remplacer le débogage itératif et expert qu'exige une ingénierie solide. L'équipe a également confirmé qu'elle utilise Codex pour construire des parties de Codex lui-même — une pratique qui soulève d'intéressantes questions de rétroaction sur les outils entraînés sur leurs propres sorties.
Pourquoi OpenAI a ouvert cela — transparence, concurrence et standards
La publication d'une analyse approfondie de l'ingénierie interne d'un produit grand public est remarquable de la part d'une entreprise qui a l'habitude de protéger ses détails opérationnels. La divulgation d'OpenAI coïncide avec une poussée plus large de l'écosystème vers des standards pour les agents : Anthropic et OpenAI supportent tous deux le MCP pour la découverte et l'invocation d'outils, et tous deux publient des clients CLI en open source afin que les développeurs puissent inspecter le comportement de bout en bout.
Cette transparence sert plusieurs publics. Les développeurs obtiennent des modèles d'implémentation et des conseils pratiques pour construire des agents fiables. Les ingénieurs axés sur la sécurité peuvent examiner les compromis entre le bac à sable et l'accès aux outils. Les concurrents et la communauté des standards peuvent itérer plus rapidement car ils n'ont pas besoin de rétro-concevoir le comportement du client pour assurer l'interopérabilité.
Conseils opérationnels pour les équipes utilisant des agents de codage
- Figer les modèles et les manifestes d'outils au sein d'une session pour maximiser les succès de cache de prompt et la stabilité des performances.
- Utiliser la compaction de contexte de manière proactive pour les tâches longues afin de contrôler les coûts de tokens et d'éviter une croissance incontrôlée des prompts.
- Limiter les permissions de l'agent et isoler les dossiers accessibles en écriture dans des bacs à sable pour réduire les effets secondaires accidentels ou malveillants.
- Prévoir et budgétiser le débogage manuel : les agents accélèrent l'échafaudage et l'itération, mais ils ne remplacent pas encore le raisonnement expert sur des bases de code complexes.
Et ensuite
L'ingénieur qui a rédigé le billet a annoncé des suites qui couvriront plus en détail l'architecture du CLI, l'implémentation des outils et le modèle de sandboxing. Ces futures publications seront importantes : à mesure que les agents accèdent plus profondément aux environnements des développeurs, la mécanique d'une exécution sûre, la provenance et l'invocation vérifiable des outils détermineront si les équipes les adoptent comme assistants ou les traitent comme des curiosités risquées.
Pour l'instant, les notes d'OpenAI transforment une partie du mystère entourant les agents de codage en leviers et boutons concrets. Ce changement permet aux équipes d'ingénierie de planifier plus facilement en fonction de compromis connus — performance, confidentialité et fragilité — plutôt que de les découvrir à leurs dépens lors de pannes en production.
La documentation de Codex CLI est une invitation : lire l'implémentation, tester les cas limites et concevoir des flux de travail qui acceptent les limites tout en tirant parti des avantages manifestes. Dans une industrie qui s'empresse d'intégrer des agents dans les outils quotidiens des développeurs, la clarté sur les modes de défaillance est la denrée la plus rare et la plus utile.
Sources
- OpenAI (documentation : « Unrolling the Codex agent loop »)
- Anthropic (spécification du Model Context Protocol et ressources Claude Code)
- Dépôts d'ingénierie d'OpenAI et notes d'implémentation de Codex CLI

Comments
No comments yet. Be the first!