Am 27. Januar 2026 veröffentlichte OpenAI ungewöhnlich detaillierte technische Notizen, die erklären, wie der Codex CLI – der Command-Line-Coding-Agent des Unternehmens – tatsächlich Konversationen führt, Tools aufruft und den Kontext verwaltet.
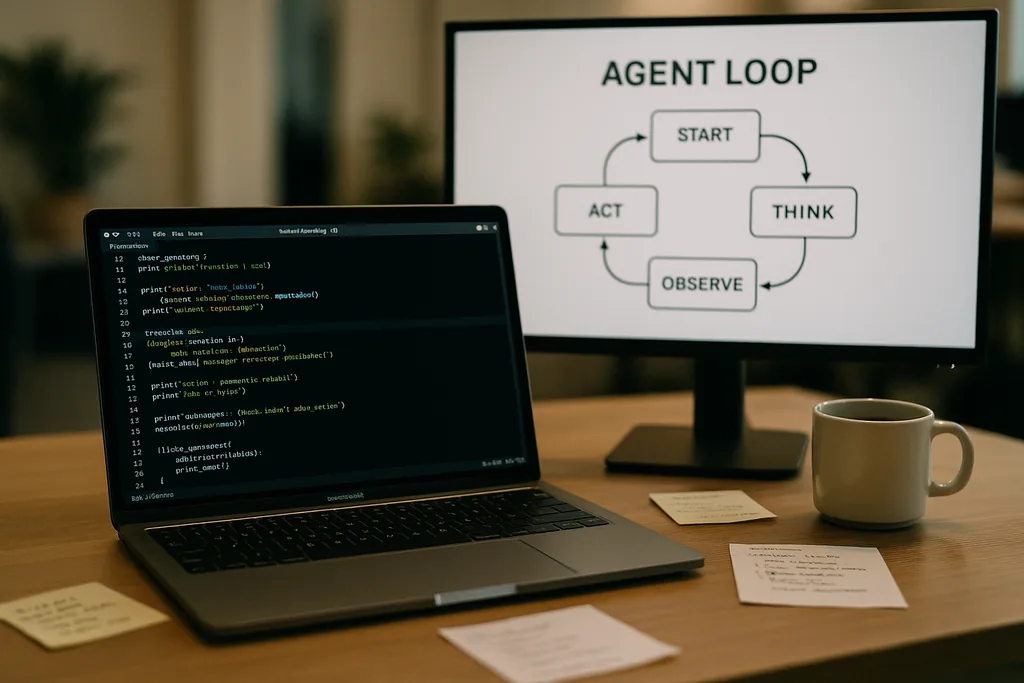
Wie der Agent-Loop aussieht
Im Zentrum von Codex CLI steht ein einfaches, sich wiederholendes Muster, das Ingenieure als „Agent-Loop“ bezeichnen: Benutzereingaben entgegennehmen, einen Prompt erstellen, das Modell um eine Antwort bitten, auf die vom Modell angeforderten Tool-Aufrufe reagieren, Tool-Ausgaben zur Konversation hinzufügen und dies wiederholen, bis das Modell eine finale Nachricht des Assistenten zurückgibt.
Dieses Muster klingt unkompliziert, aber die Dokumentation erläutert viele kleine Designentscheidungen, die zusammen die Leistung und Zuverlässigkeit prägen. Der an das Modell gesendete Prompt ist kein einzelner Textblock; er ist ein strukturierter Aufbau aus priorisierten Komponenten. System-, Entwickler-, Assistenten- und Benutzerrollen bestimmen, welche Anweisungen Vorrang haben. Ein Tools-Feld kündigt verfügbare Funktionen an – lokale Shell-Befehle, Planungsprogramme, Web-Suche und benutzerdefinierte Dienste, die über Model Context Protocol (MCP)-Server bereitgestellt werden. Der Umgebungskontext beschreibt Sandbox-Berechtigungen, Arbeitsverzeichnisse und welche Dateien oder Prozesse für den Agenten sichtbar sind.
Tool-Aufrufe, MCP und Sandboxing
Wenn das Modell einen Tool-Aufruf ausgibt, führt Codex dieses Tool in einer kontrollierten Umgebung (seiner Sandbox) aus, erfasst die Ausgabe und fügt das Ergebnis der Konversation hinzu. Benutzerdefinierte Tools können über MCP-Server implementiert werden – ein offener Standard, den mehrere Unternehmen übernommen haben –, die es einem Modell ermöglichen, Funktionen jenseits einer einfachen Shell zu entdecken und aufzurufen. Die Dokumentation erörtert auch spezifische Fehler, die das Team beim Erstellen dieser Integrationen entdeckt hat – beispielsweise eine inkonsistente Aufzählung von MCP-Tools –, die gepatcht werden mussten.
OpenAI merkt an, dass Sandboxing und Tool-Zugriff aktive Themen für nachfolgende Beiträge sind. Die ursprüngliche Dokumentation konzentriert sich eher auf die Mechanik des Loops und die Leistungsoptimierung als auf das vollständige Bedrohungsmodell von Agenten mit Schreibzugriff auf ein Dateisystem oder Netzwerkdienste.
Zustandslose Anfragen, Datenschutzentscheidungen und die Kosten des Kontext-Kopierens
Diese Inflation ist nicht linear. Jede Runde fügt Tokens hinzu, und da jede Runde die vorherigen Runden vollständig enthält, tendiert die Prompt-Größe zu einem quadratischen Wachstum im Verhältnis zur Anzahl der Runden. Das Team dokumentiert dies explizit und erklärt, wie sie dies mit Kontext-Kompaktierung und Prompt-Caching abmildern.
Prompt-Caching und exakte Präfixe
Prompt-Caching ist eine pragmatische Optimierung: Wenn eine neue Anfrage ein exakter Präfix eines zuvor zwischengespeicherten Prompts ist, kann der Anbieter die Berechnung wiederverwenden und Ergebnisse schneller liefern. Caches erfordern jedoch Starrheit. Jede Änderung an den verfügbaren Tools, ein Modellwechsel oder sogar eine Anpassung der Sandbox-Konfiguration kann den Präfix ungültig machen und einen Cache-Hit in einen kostspieligen Miss verwandeln. OpenAI-Ingenieure warnen davor, dass Entwickler Neukonfigurationen während einer Konversation vermeiden sollten, wenn sie eine konsistente Latenz benötigen.
Cache-Hits hängen vom exakten Prefix-Matching ab, daher gehören das Fixieren (Pinning) von Tool-Manifesten und die Beibehaltung der Modellauswahl innerhalb einer laufenden Interaktion zu den sinnvollen Praktiken. Wenn Cache-Misses häufig auftreten, fällt das System bei jedem Aufruf auf die vollständige Neuverarbeitung zurück – genau dann, wenn Entwickler erwarten, dass der Agent schnell reagiert.
Kontext-Kompaktierung: Die Vergangenheit komprimieren, ohne die Bedeutung zu verlieren
Um das Token-Wachstum zu bewältigen, implementiert Codex eine automatische Kontext-Kompaktierung. Anstatt dies einem Benutzerbefehl zu überlassen, ruft das CLI einen spezialisierten API-Endpunkt auf, der ältere Konversationsrunden in ein verschlüsseltes Inhaltselement komprimiert, während das zusammengefasste Wissen, das das Modell zum Fortfahren benötigt, erhalten bleibt. Frühere Versionen erforderten eine manuelle Kompaktierung durch den Benutzer; der neuere Ansatz verlagert den Prozess in einen API-Aufruf, der das Arbeitsgedächtnis des Modells bewahrt.
Kompaktierung reduziert die Token-Kosten, bringt aber einige Feinheiten mit sich: Zusammenfassungen müssen originalgetreu genug sein, um nachgelagerte Halluzinationen zu vermeiden, Verschlüsselungseigenschaften müssen den Datenschutzbeschränkungen entsprechen, und Kompaktierungsheuristiken müssen entscheiden, welche Teile des Zustands wesentlich und welche verzichtbar sind. Die Dokumentation kennzeichnet diese als offene technische Entscheidungen und nicht als fertige Designs.
Praktische Grenzen und Entwicklererfahrung
Die Notizen von OpenAI sind offen in Bezug auf Stärken und Schwächen. Für einfache Aufgaben – die Art von Scaffolding, Boilerplate oder schnellem Prototyping, in denen Coding-Agenten hervorragend sind – ist Codex schnell und nützlich. Für tiefere, kontextintensive technische Arbeiten, die das Modell in seinen Trainingsdaten nicht gesehen hat, ist der Agent fragil. Er wird vielversprechende Grundgerüste (Scaffolds) erstellen, dann aber stocken oder fehlerhafte Schritte ausgeben, die ein menschliches Debugging erfordern.
Ingenieure, die Codex intern testeten, stellten fest, dass der Agent die anfängliche Projekterstellung dramatisch beschleunigen kann, aber noch nicht das iterative Experten-Debugging ersetzen kann, das solide Technik erfordert. Das Team bestätigte auch, dass sie Codex verwenden, um Teile von Codex selbst zu bauen – eine Praxis, die interessante Fragen zum Feedback von Tools aufwirft, die auf ihren eigenen Ausgaben trainiert wurden.
Warum OpenAI dies offenlegte – Transparenz, Wettbewerb und Standards
Die Veröffentlichung eines tiefen Einblicks in die interne Technik eines Konsumprodukts ist bemerkenswert für ein Unternehmen, das seine operativen Details normalerweise unter Verschluss hält. Die Offenlegung von OpenAI fällt mit einem breiteren Vorstoß des Ökosystems in Richtung Agenten-Standards zusammen: Anthropic und OpenAI unterstützen beide MCP für die Entdeckung und den Aufruf von Tools und veröffentlichen beide CLI-Clients als Open Source, damit Entwickler das Verhalten durchgängig überprüfen können.
Die Transparenz dient mehreren Zielgruppen. Entwickler erhalten Implementierungsmuster und praktische Ratschläge für den Aufbau zuverlässiger Agenten. Sicherheitsbewusste Ingenieure können die Abwägungen zwischen Sandbox- und Tool-Zugriff prüfen. Wettbewerber und die Standardisierungsgemeinschaft können schneller iterieren, da sie das Verhalten der Clients nicht erst per Reverse Engineering entschlüsseln müssen, um Interoperabilität zu gewährleisten.
Operative Ratschläge für Teams, die Coding-Agenten einsetzen
- Fixieren (Pinning) von Modellen und Tool-Manifesten innerhalb einer Sitzung, um Prompt-Cache-Hits und stabile Leistung zu maximieren.
- Kontext-Kompaktierung proaktiv für lange Aufgaben nutzen, um Token-Kosten zu kontrollieren und unkontrolliertes Prompt-Wachstum zu vermeiden.
- Agentenberechtigungen einschränken und beschreibbare Ordner in Sandboxes isolieren, um versehentliche oder böswillige Nebenwirkungen zu reduzieren.
- Manuelles Debugging einplanen: Agenten beschleunigen das Scaffolding und die Iteration, ersetzen aber noch nicht das fachkundige Denken bei komplexen Codebasen.
Was kommt als Nächstes
Der Ingenieur, der den Beitrag verfasst hat, signalisierte Fortsetzungen, die die Architektur des CLI, die Tool-Implementierung und das Sandboxing-Modell genauer behandeln werden. Diese zukünftigen Beiträge werden wichtig sein: Da Agenten tieferen Zugriff auf die Umgebungen von Entwicklern erhalten, wird die Mechanik der sicheren Ausführung, der Herkunft (Provenance) und des verifizierbaren Tool-Aufrufs darüber entscheiden, ob Teams sie als Assistenten akzeptieren oder als riskante Kuriositäten behandeln.
Vorerst verwandeln die Notizen von OpenAI einen Teil der Mystik um Coding-Agenten in konkrete Regler und Hebel. Dieser Wandel macht es für Ingenieurteams einfacher, bekannte Kompromisse – Leistung, Datenschutz und Fragilität – einzuplanen, anstatt sie auf die harte Tour während Produktionsausfällen zu entdecken.
Die Dokumentation von Codex CLI ist eine Einladung: Lesen Sie die Implementierung, testen Sie die Grenzfälle und entwerfen Sie Workflows, die die Grenzen akzeptieren und gleichzeitig die klaren Vorteile nutzen. In einer Branche, die darum wettet, Agenten in alltägliche Entwickler-Tools zu integrieren, ist Klarheit über Fehlermodi das seltenste und nützlichste Gut.
Quellen
- OpenAI (Dokumentation: „Unrolling the Codex agent loop“)
- Anthropic (Model Context Protocol-Spezifikation und Claude Code-Materialien)
- OpenAI-Engineering-Repositories und Codex CLI-Implementierungsnotizen

Kommentare
Noch keine Kommentare. Seien Sie der Erste!