Em 27 de janeiro de 2026, a OpenAI publicou notas de engenharia excepcionalmente detalhadas explicando como o Codex CLI — o agente de codificação de linha de comando da empresa — realmente executa conversas, faz chamadas de ferramentas e gerencia o contexto.
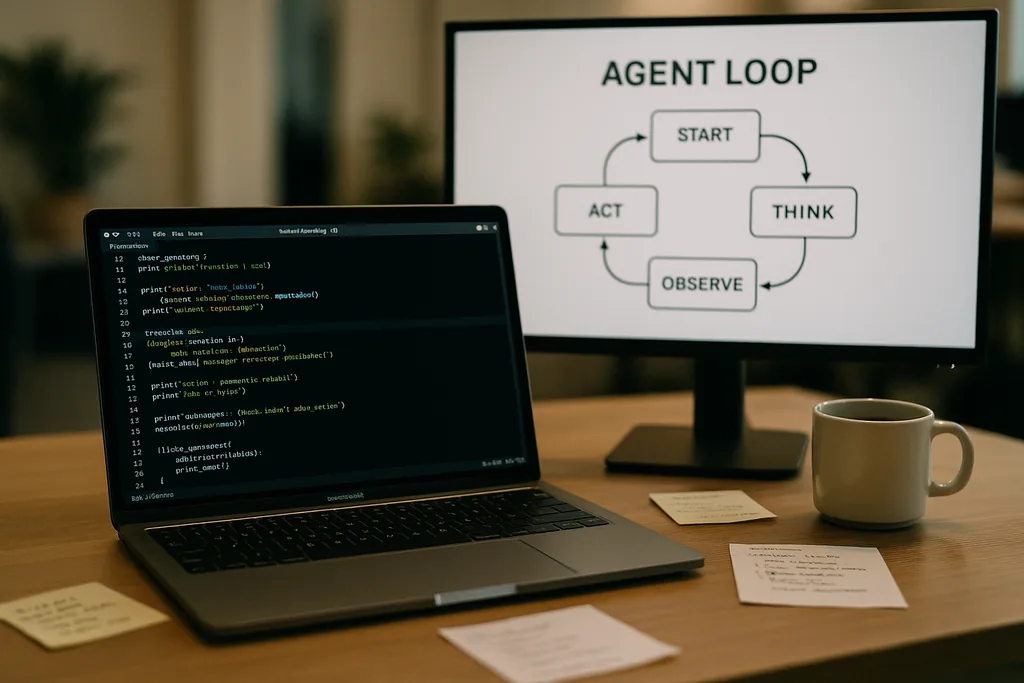
Como é o loop do agente
No coração do Codex CLI está um padrão de repetição simples que os engenheiros chamam de "loop do agente": aceitar a entrada do usuário, elaborar um prompt, solicitar uma resposta ao modelo, agir de acordo com as chamadas de ferramentas que o modelo solicita, anexar as saídas das ferramentas à conversa e repetir até que o modelo retorne uma mensagem final do assistente.
Esse padrão parece simples, mas a documentação detalha muitas pequenas decisões de design que, juntas, moldam o desempenho e a confiabilidade. O prompt enviado ao modelo não é um único bloco de texto; é uma montagem estruturada de componentes priorizados. As funções de sistema, desenvolvedor, assistente e usuário determinam quais instruções têm precedência. Um campo de ferramentas anuncia as funções disponíveis — comandos de shell locais, utilitários de planejamento, busca na web e serviços personalizados expostos por meio de servidores Model Context Protocol (MCP). O contexto do ambiente descreve as permissões de sandbox, diretórios de trabalho e quais arquivos ou processos estão visíveis para o agente.
Chamadas de ferramentas, MCP e sandboxing
Quando o modelo emite uma chamada de ferramenta, o Codex executa essa ferramenta em um ambiente controlado (sua sandbox), captura a saída e anexa o resultado à conversa. Ferramentas personalizadas podem ser implementadas por meio de servidores MCP — um padrão aberto que várias empresas adotaram — que permitem que um modelo descubra e invoque capacidades além de um simples shell. A documentação também discute bugs específicos que a equipe descobriu ao construir essas integrações — uma enumeração inconsistente de ferramentas MCP, por exemplo — que precisaram ser corrigidos.
A OpenAI observa que o sandboxing e o acesso a ferramentas são áreas ativas para postagens de acompanhamento. A documentação inicial foca na mecânica do loop e na mitigação de desempenho, em vez do modelo de ameaça completo de agentes com acesso de gravação a um sistema de arquivos ou serviços de rede.
Solicitações stateless, escolhas de privacidade e o custo de copiar o contexto
Essa inflação não é linear. Cada turno adiciona tokens e, como cada turno inclui os turnos anteriores na íntegra, o tamanho do prompt tende a um crescimento quadrático em relação ao número de turnos. A equipe documenta isso explicitamente e explica como mitiga o problema com compactação de contexto e cache de prompts.
Cache de prompts e prefixos exatos
O cache de prompts é uma otimização pragmática: se uma nova solicitação for um prefixo exato de um prompt armazenado anteriormente em cache, o provedor pode reutilizar a computação e retornar os resultados mais rapidamente. Mas os caches exigem rigidez. Qualquer alteração nas ferramentas disponíveis, uma troca de modelo ou até mesmo um ajuste na configuração da sandbox pode invalidar o prefixo e transformar um acerto no cache (cache hit) em uma falha dispendiosa (cache miss). Os engenheiros da OpenAI alertam que os desenvolvedores devem evitar reconfigurações no meio da conversa quando precisam de latência consistente.
Os acertos no cache dependem da correspondência exata do prefixo, portanto, as práticas recomendadas incluem fixar manifestos de ferramentas e manter constante a seleção do modelo dentro de uma interação em andamento. Quando ocorrem falhas de cache frequentes, o sistema degrada para o reprocessamento total em cada chamada — exatamente quando os desenvolvedores esperam que o agente pareça ágil.
Compactação de contexto: comprimindo o passado sem perder o significado
Para gerenciar o crescimento de tokens, o Codex implementa a compactação automática de contexto. Em vez de deixar para um comando do usuário, o CLI chama um endpoint de API especializado que comprime turnos de conversa mais antigos em um item de conteúdo criptografado, mantendo o conhecimento resumido que o modelo precisa para prosseguir. Versões anteriores exigiam compactação manual do usuário; a abordagem mais recente move o processo para uma chamada de API que preserva a memória de trabalho do modelo.
A compactação reduz o custo de tokens, mas introduz algumas sutilezas: os resumos devem ser fiéis o suficiente para evitar alucinações futuras, os adereços de criptografia precisam corresponder às restrições de privacidade e as heurísticas de compactação devem decidir quais partes do estado são essenciais em oposição às dispensáveis. A documentação aponta estas como escolhas de engenharia em aberto, em vez de designs definitivos.
Limites práticos e experiência do desenvolvedor
As notas da OpenAI são francas sobre pontos fortes e fracos. Para tarefas diretas — o tipo de estruturação (scaffolding), código repetitivo (boilerplate) ou prototipagem rápida em que os agentes de codificação se destacam — o Codex é rápido e útil. Para trabalhos de engenharia mais profundos e pesados em contexto que o modelo não viu em seus dados de treinamento, o agente é frágil. Ele gerará estruturas promissoras e, em seguida, travará ou emitirá etapas incorretas que precisam de depuração humana.
Engenheiros que testaram o Codex internamente descobriram que o agente pode acelerar dramaticamente a criação inicial de projetos, mas ainda não pode substituir a depuração iterativa e especializada que uma engenharia sólida exige. A equipe também confirmou que usa o Codex para construir partes do próprio Codex — uma prática que levanta questões interessantes de feedback sobre ferramentas treinadas em seus próprios resultados.
Por que a OpenAI abriu isso — transparência, concorrência e padrões
Publicar um mergulho profundo na engenharia interna de um produto de consumo é notável vindo de uma empresa que normalmente protege seus detalhes operacionais. A divulgação da OpenAI coincide com um impulso mais amplo do ecossistema em direção a padrões de agentes: Anthropic e OpenAI suportam o MCP para descoberta e invocação de ferramentas, e ambas publicam clientes de CLI como código aberto para que os desenvolvedores possam inspecionar o comportamento de ponta a ponta.
A transparência serve a vários públicos. Os desenvolvedores obtêm padrões de implementação e conselhos práticos para construir agentes confiáveis. Engenheiros focados em segurança podem examinar as compensações entre sandbox e acesso a ferramentas. Os concorrentes e a comunidade de padrões podem iterar mais rápido porque não precisam fazer engenharia reversa no comportamento do cliente para interoperar.
Conselhos operacionais para equipes que usam agentes de codificação
- Fixe modelos e manifestos de ferramentas dentro de uma sessão para maximizar os acertos de cache de prompt e o desempenho estável.
- Use a compactação de contexto proativamente para tarefas longas para controlar os custos de tokens e evitar o crescimento descontrolado do prompt.
- Limite as permissões do agente e isole pastas graváveis em sandboxes para reduzir efeitos colaterais acidentais ou maliciosos.
- Espere e reserve tempo para depuração manual: os agentes aceleram a estruturação e a iteração, mas ainda não substituem o raciocínio especializado em bases de código complexas.
O que vem a seguir
O engenheiro que escreveu a postagem sinalizou acompanhamentos que cobrirão a arquitetura do CLI em maior profundidade, a implementação de ferramentas e o modelo de sandboxing. Essas entradas futuras serão importantes: à medida que os agentes ganham acesso mais profundo aos ambientes dos desenvolvedores, a mecânica de execução segura, procedência e invocação verificável de ferramentas determinarão se as equipes os adotarão como assistentes ou os tratarão como curiosidades arriscadas.
Por enquanto, as notas da OpenAI convertem parte da mística em torno dos agentes de codificação em botões e alavancas concretos. Essa mudança torna mais fácil para as equipes de engenharia planejarem em torno de compensações conhecidas — desempenho, privacidade e fragilidade — em vez de descobri-las da maneira mais difícil durante interrupções na produção.
A documentação do Codex CLI é um convite: leia a implementação, teste os casos extremos e projete fluxos de trabalho que aceitem os limites enquanto aproveitam os benefícios claros. Em uma indústria que corre para colocar agentes nas ferramentas diárias dos desenvolvedores, a clareza sobre os modos de falha é a mercadoria mais rara e útil.
Fontes
- OpenAI (documentação: "Unrolling the Codex agent loop")
- Anthropic (especificação do Model Context Protocol e materiais do Claude Code)
- Repositórios de engenharia da OpenAI e notas de implementação do Codex CLI

Comments
No comments yet. Be the first!