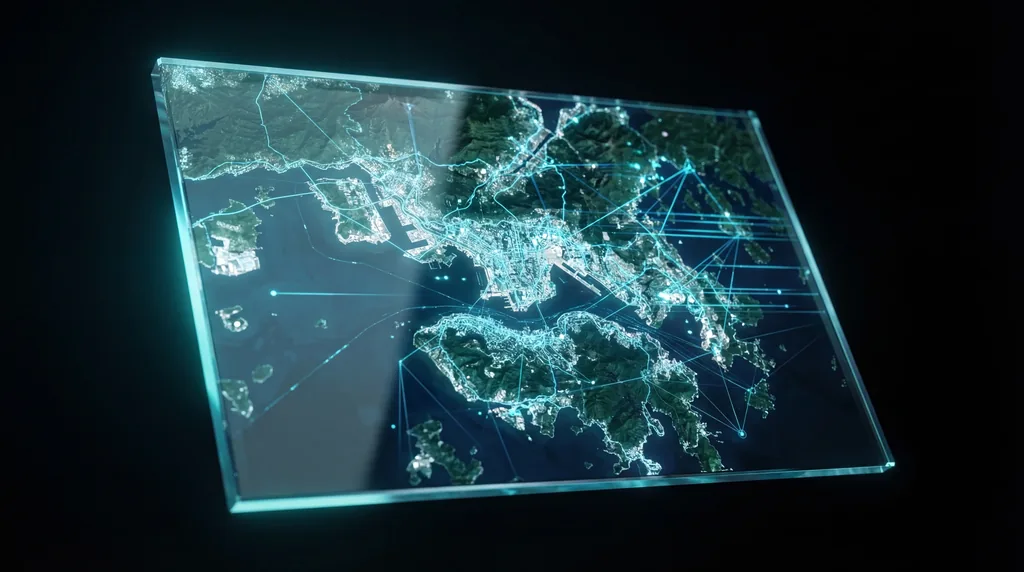

Więcej niż mapowanie: Nowa sztuczna inteligencja typu „zero-shot” potrafi wnioskować na podstawie zdjęć satelitarnych bez uprzedniego szkolenia
Teledetekcja przechodzi obecnie zmianę paradygmatu wraz z wprowadzeniem GeoSeg, czyli beztreningowej struktury typu zero-shot, zaprojektowanej do przeprowadzania segmentacji opartej na wnioskowaniu w obrazach satelitarnych. W przeciwieństwie do tradycyjnych modeli, które wymagają szeroko zakrojonego douczania dla nowych kategorii obiektów, naukowcy Lifan Jiang, Yuhang Pei i Tianrun Wu opracowali system, który interpretuje złożone instrukcje ludzkie w celu identyfikacji konkretnych struktur i cech środowiskowych. Ten przełom pozwala Multimodalnym Wielkim Modelom Językowym (MLLM) na lokalizowanie obiektów poprzez zrozumienie ich ról funkcjonalnych i kontekstu przestrzennego, zamiast polegania na statycznych etykietach na poziomie pikseli.
Ewolucja obserwacji Ziemi od dawna była hamowana przez ograniczenia uczenia nadzorowanego, które wymaga ogromnych, anotowanych przez ludzi zbiorów danych dla każdego konkretnego zadania. Choć sztuczna inteligencja stała się biegła w identyfikowaniu powszechnych obiektów, takich jak „samochody” czy „budynki” na poziomych zdjęciach z poziomu gruntu, unikalna geometria widoków z góry stanowi istotną barierę. GeoSeg rozwiązuje ten problem poprzez oddzielenie procesu wnioskowania od zadania lokalizacji, co pozwala AI „przemyśleć” zapytanie przed wskazaniem odpowiednich pikseli, skutecznie wychodząc poza proste dopasowywanie wzorców w stronę autentycznego wnioskowania przestrzennego.
Dlaczego segmentacja oparta na wnioskowaniu jest wyzwaniem w teledetekcji?
Segmentacja oparta na wnioskowaniu w teledetekcji jest wyzwaniem ze względu na perspektywę z góry, która tworzy strukturalną lukę domenową względem scen naturalnych zorientowanych grawitacyjnie, co sprawia trudności nowoczesnym multimodalnym wielkim modelom językowym (MLLM). Dodatkowe trudności obejmują słabe różnice w teksturze między obiektami oraz niedobór zbiorów danych zorientowanych na wnioskowanie, co czyni podejścia wymagające intensywnego trenowania dla złożonej lokalizacji opartej na instrukcjach wysoce niepraktycznymi.
Standardowe modele wizji komputerowej są zazwyczaj trenowane na zbiorach danych takich jak COCO lub ImageNet, które składają się z fotografii z poziomu gruntu, gdzie kierunki „góra” i „dół” są jasno zdefiniowane przez grawitację. W przeciwieństwie do tego, Inteligencja Satelitarna opiera się na widoku w nadirze lub poza nadirem, gdzie obiekty wydają się niezmiennicze rotacyjnie. Oznacza to, że budynek wygląda tak samo bez względu na orientację czujnika, co często dezorientuje modele MLLM zoptymalizowane pod kątem „naturalnej” orientacji zdjęć koncentrujących się na perspektywie ludzkiej. Ponadto, wysoki koszt generowania danych „wnioskowych” – gdzie ekspert musi wyjaśnić, dlaczego dany obszar jest zagrożony powodzią lub jest placem budowy – sprawia, że tradycyjne szkolenie nadzorowane jest ekonomicznie niewykonalne dla większości organizacji.
Jakie wyzwania specyficzne dla domeny, takie jak widok z góry, rozwiązuje GeoSeg?
GeoSeg rozwiązuje wyzwania specyficzne dla domeny, takie jak widok z góry, poprzez moduł korekcji współrzędnych uwzględniający błąd systematyczny, który koryguje systematyczne przesunięcia lokalizacji spowodowane obrazowaniem typu top-down. Stosuje również mechanizm promptowania dwutorowego, aby połączyć intencję semantyczną z precyzyjnymi wskazówkami przestrzennymi, co poprawia dokładność lokalizacji i redukuje błędy, takie jak nadmierna segmentacja lub łączenie odrębnych obiektów w złożonych scenach.
Jednym z głównych wkładów technicznych pracy autorstwa Jiang et al. jest moduł bias-aware coordinate refinement (korekcja współrzędnych uwzględniająca błąd systematyczny). Komponent ten działa jak soczewka korygująca, identyfikując systematyczny „dryf”, który występuje, gdy model MLLM próbuje przypisać koncepcję lingwistyczną do określonego zestawu współrzędnych na mapie satelitarnej. Ponieważ dane z teledetekcji obejmują różne skale i rozdzielczości, GeoSeg wykorzystuje tę korekcję, aby upewnić się, że ramki ograniczające i maski segmentacji idealnie pokrywają się z fizycznymi granicami obiektów, nawet gdy tekstury wizualne są subtelne lub nakładają się na siebie.
Mechanizm promptowania dwutorowego dodatkowo usprawnia ten proces, rozdzielając „proces myślowy” AI na dwie ścieżki: jedną skupioną na wysokopoziomowej intencji semantycznej (co użytkownik chce znaleźć) oraz drugą na wskazówkach przestrzennych (gdzie faktycznie znajdują się piksele). Łącząc te dwie drogi, GeoSeg unika typowej pułapki „halucynowania” obiektów, których nie ma, lub pomijania kluczowych szczegółów przesłoniętych przez cienie lub zakłócenia atmosferyczne.
Czym jest benchmark GeoSeg-Bench?
GeoSeg-Bench to benchmark diagnostyczny wprowadzony wraz ze strukturą GeoSeg, składający się z 810 par obraz-zapytanie zaprojektowanych z uwzględnieniem hierarchicznych poziomów trudności. Mierzy on postęp w możliwościach segmentacji typu zero-shot poprzez testowanie modeli w różnorodnych zadaniach zorientowanych na wnioskowanie, zapewniając standaryzowany miernik tego, jak dobrze AI potrafi interpretować otwarte zapytania ludzkie w obrazowaniu satelitarnym.
Stworzenie GeoSeg-Bench zapewnia społeczności naukowej rygorystyczny sposób oceny uczenia typu zero-shot w kontekście obserwacji Ziemi. Benchmark jest zorganizowany hierarchicznie, od prostych zadań identyfikacji po złożone scenariusze wymagające wieloetapowej dedukcji logicznej. Na przykład zapytanie może prosić system o „znalezienie wszystkich budynków mieszkalnych znajdujących się w promieniu 50 metrów od linii brzegowej, które nie posiadają ochronnych falochronów” – zadanie to tradycyjnie wymagałoby wielu warstw ręcznej analizy w systemach informacji geograficznej (GIS). Prześcigając istniejące modele bazowe w tym benchmarku, GeoSeg wykazał solidną zdolność do generalizacji w różnych lokalizacjach geograficznych i typach czujników bez jakiegokolwiek wcześniejszego dostrajania.
Jak GeoSeg zmieni przyszłość teledetekcji?
Przyszłe zastosowania GeoSeg w teledetekcji obejmują usprawnienie reagowania kryzysowego poprzez złożone zapytania w języku naturalnym oraz wspieranie planowania urbanistycznego bez konieczności ciągłego douczania modeli. To beztreningowe podejście pozwala na natychmiastowe wdrożenie w szybko zmieniających się środowiskach, gdzie szybkość i zdolność adaptacji są kluczowe dla dokładnego monitorowania środowiska i zarządzania kryzysowego.
Implikacje dla obserwacji Ziemi są ogromne, szczególnie w zastosowaniach humanitarnych i środowiskowych. W następstwie klęski żywiołowej służby ratunkowe mogłyby użyć GeoSeg, aby zapytać: „Zidentyfikuj wszystkie przejezdne drogi, które nie są zablokowane przez gruz lub wodę”, co pozwoliłoby AI na natychmiastowe przetworzenie satelitarnych transmisji w czasie rzeczywistym bez czekania tygodniami, aż programista wyszkoli nowy model. Ta demokratyzacja Inteligencji Satelitarnej oznacza, że osoby niebędące ekspertami mogą wchodzić w interakcję ze złożonymi danymi geoprzestrzennymi, używając jedynie języka naturalnego.
W miarę jak naukowcy patrzą w przyszłość, uwaga prawdopodobnie skupi się na integrowaniu danych czasowych – co pozwoli GeoSeg na wnioskowanie o tym, jak krajobraz zmieniał się w czasie. Łącząc możliwości uczenia typu zero-shot modeli MLLM z precyzją teledetekcji, dziedzina ta zmierza ku przyszłości, w której AI nie tylko widzi świat z góry, ale naprawdę rozumie zawiłe szczegóły systemów ludzkich i naturalnych, które obserwuje.

{kind=link}
Comments
No comments yet. Be the first!