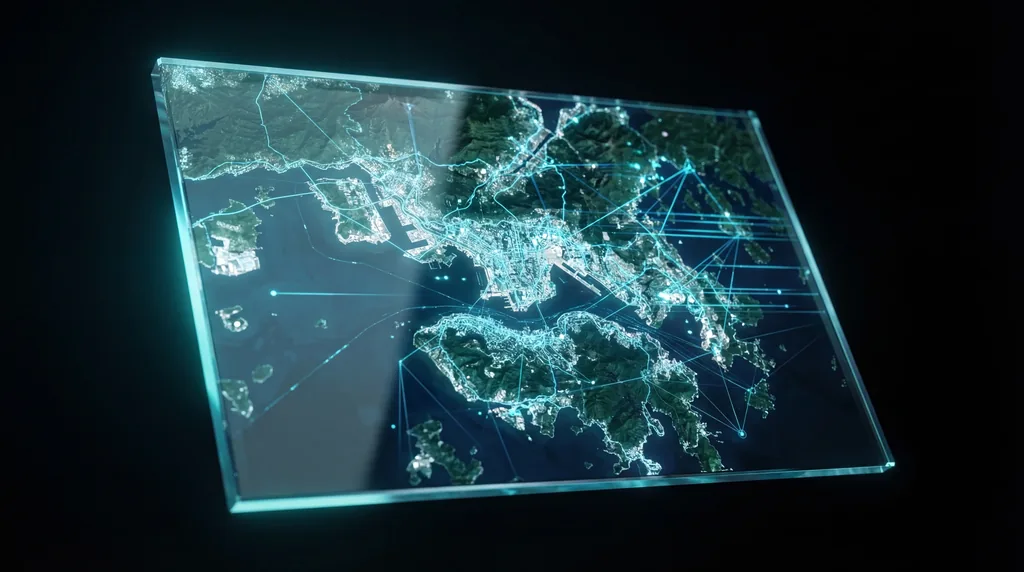

Oltre la mappatura: una nuova IA "Zero-Shot" è in grado di ragionare sulle immagini satellitari senza addestramento preventivo
L'analisi di telerilevamento (Remote Sensing) sta vivendo un cambio di paradigma con l'introduzione di GeoSeg, un framework zero-shot e senza addestramento (training-free) progettato per eseguire la segmentazione guidata dal ragionamento nelle immagini satellitari. A differenza dei modelli tradizionali che richiedono un ampio riaddestramento per nuove categorie di oggetti, i ricercatori Lifan Jiang, Yuhang Pei e Tianrun Wu hanno sviluppato un sistema che interpreta complesse istruzioni umane per identificare strutture specifiche e caratteristiche ambientali. Questa svolta consente ai modelli linguistici multimodali di grandi dimensioni (MLLM) di localizzare gli oggetti comprendendo i loro ruoli funzionali e il contesto spaziale, piuttosto che fare affidamento su etichette statiche a livello di pixel.
L'evoluzione dell'osservazione della Terra è stata a lungo ostacolata dai limiti dell'apprendimento supervisionato, che richiede enormi dataset annotati da esseri umani per ogni compito specifico. Sebbene l'IA sia diventata esperta nell'identificare oggetti comuni come "auto" o "edifici" in foto orizzontali a livello del suolo, la geometria unica delle viste dall'alto rappresenta una barriera significativa. GeoSeg affronta questo problema separando il processo di ragionamento dal compito di localizzazione, consentendo all'IA di "pensare" attraverso una query prima di individuare i pixel rilevanti, passando efficacemente dal semplice pattern matching a un autentico ragionamento spaziale.
Perché la segmentazione guidata dal ragionamento è complessa nel telerilevamento?
La segmentazione guidata dal ragionamento nel telerilevamento è complessa a causa della prospettiva dall'alto, che crea un divario di dominio strutturale rispetto alle scene naturali allineate alla gravità, mettendo in difficoltà i moderni modelli linguistici multimodali di grandi dimensioni (MLLM). Ulteriori difficoltà includono le deboli differenze di texture tra gli oggetti e la scarsità di dataset orientati al ragionamento, rendendo gli approcci ad alta intensità di addestramento per la localizzazione basata su istruzioni complesse estremamente impraticabili.
I modelli standard di computer vision sono tipicamente addestrati su dataset come COCO o ImageNet, che consistono in fotografie a livello del suolo dove l'"alto" e il "basso" sono chiaramente definiti dalla gravità. Al contrario, l'intelligenza satellitare si basa su un punto di vista nadirale o fuori nadir in cui gli oggetti appaiono invarianti alla rotazione. Ciò significa che un edificio appare identico indipendentemente dall'orientamento del sensore, un fattore che spesso confonde gli MLLM ottimizzati per l'orientamento "naturale" delle foto incentrate sull'uomo. Inoltre, l'elevato costo di generazione dei dati di "ragionamento" — in cui un esperto deve spiegare perché una certa area è a rischio inondazione o un sito di costruzione — rende l'addestramento supervisionato tradizionale economicamente insostenibile per la maggior parte delle organizzazioni.
Quali sfide specifiche del dominio affronta GeoSeg, come i punti di vista dall'alto?
GeoSeg affronta le sfide specifiche del dominio come i punti di vista dall'alto attraverso il raffinamento delle coordinate consapevole del bias, che corregge gli spostamenti sistematici di localizzazione (grounding) causati dalle immagini zenitali. Impiega inoltre un meccanismo di prompting a doppia via per fondere l'intento semantico con indizi spaziali a grana fine, migliorando la precisione della localizzazione e riducendo errori come la sovra-segmentazione o la fusione di oggetti distinti in scene complesse.
Uno dei principali contributi tecnici del lavoro di Jiang et al. è il modulo di raffinamento delle coordinate consapevole del bias. Questo componente agisce come una lente correttiva, identificando la "deriva" sistematica che si verifica quando un MLLM tenta di mappare un concetto linguistico a un set specifico di coordinate su una mappa satellitare. Poiché i dati di telerilevamento coinvolgono scale e risoluzioni variabili, GeoSeg utilizza questo raffinamento per garantire che i riquadri di delimitazione (bounding box) e le maschere di segmentazione si allineino perfettamente con i confini fisici degli oggetti, anche quando le texture visive sono sottili o sovrapposte.
Il meccanismo di prompting a doppia via potenzia ulteriormente questo aspetto dividendo il "processo di pensiero" dell'IA in due percorsi: uno focalizzato sull'intento semantico di alto livello (ciò che l'utente vuole trovare) e l'altro sugli indizi spaziali (dove si trovano effettivamente i pixel). Fondendo questi due percorsi, GeoSeg evita la trappola comune di "allucinare" oggetti che non esistono o di perdere dettagli critici oscurati da ombre o interferenze atmosferiche.
Cos'è il benchmark GeoSeg-Bench?
GeoSeg-Bench è un benchmark diagnostico introdotto con il framework GeoSeg, composto da 810 coppie immagine-query progettate con livelli di difficoltà gerarchici. Misura i progressi nelle capacità di segmentazione zero-shot testando i modelli su diversi compiti orientati al ragionamento, fornendo una metrica standardizzata su quanto bene l'IA possa interpretare query umane aperte nelle immagini satellitari.
La creazione di GeoSeg-Bench fornisce alla comunità scientifica un modo rigoroso per valutare lo Zero-Shot Learning nel contesto dell'osservazione della Terra. Il benchmark è organizzato gerarchicamente, spaziando da semplici compiti di identificazione a scenari complessi che richiedono deduzioni logiche in più passaggi. Ad esempio, una query potrebbe chiedere al sistema di "trovare tutti gli edifici residenziali che si trovano entro 50 metri da una costa ma mancano di barriere protettive", un compito che tradizionalmente richiederebbe più livelli di analisi manuale dei sistemi informativi geografici (GIS). Superando i baseline esistenti su questo benchmark, GeoSeg ha dimostrato una robusta capacità di generalizzare attraverso diverse aree geografiche e tipi di sensori senza alcun fine-tuning preventivo.
In che modo GeoSeg trasformerà il futuro del telerilevamento?
Le future applicazioni di GeoSeg nel telerilevamento includono la semplificazione della risposta ai disastri attraverso query complesse in linguaggio naturale e il potenziamento della pianificazione urbana senza la necessità di un costante riaddestramento del modello. Questo approccio senza addestramento consente un dispiegamento immediato in ambienti che cambiano rapidamente, dove velocità e adattabilità sono fondamentali per un monitoraggio ambientale accurato e la gestione delle emergenze.
Le implicazioni per l'osservazione della Terra sono vaste, in particolare per le applicazioni umanitarie e ambientali. All'indomani di un disastro naturale, i soccorritori potrebbero usare GeoSeg per chiedere: "Identifica tutte le strade accessibili che non sono bloccate da detriti o acqua", consentendo all'IA di elaborare immediatamente i feed satellitari in tempo reale senza aspettare settimane che uno sviluppatore addestri un nuovo modello. Questa democratizzazione dell'intelligenza satellitare significa che anche i non esperti possono interagire con dati geospaziali complessi usando nient'altro che il linguaggio naturale.
Mentre i ricercatori guardano alle direzioni future, l'attenzione si sposterà probabilmente sull'integrazione dei dati temporali, consentendo a GeoSeg di ragionare su come un paesaggio sia cambiato nel tempo. Combinando le capacità di Zero-Shot Learning degli MLLM con la precisione del telerilevamento, il campo si sta muovendo verso un futuro in cui l'IA non si limita a vedere il mondo dall'alto, ma ne comprende veramente gli intricati dettagli dei sistemi umani e naturali che osserva.

{kind=link}
Comments
No comments yet. Be the first!